Timeline
Ongoing
Role
Cofounder/Product Lead
Team
1x Engineer
Tags
AR, Image recognition, AI

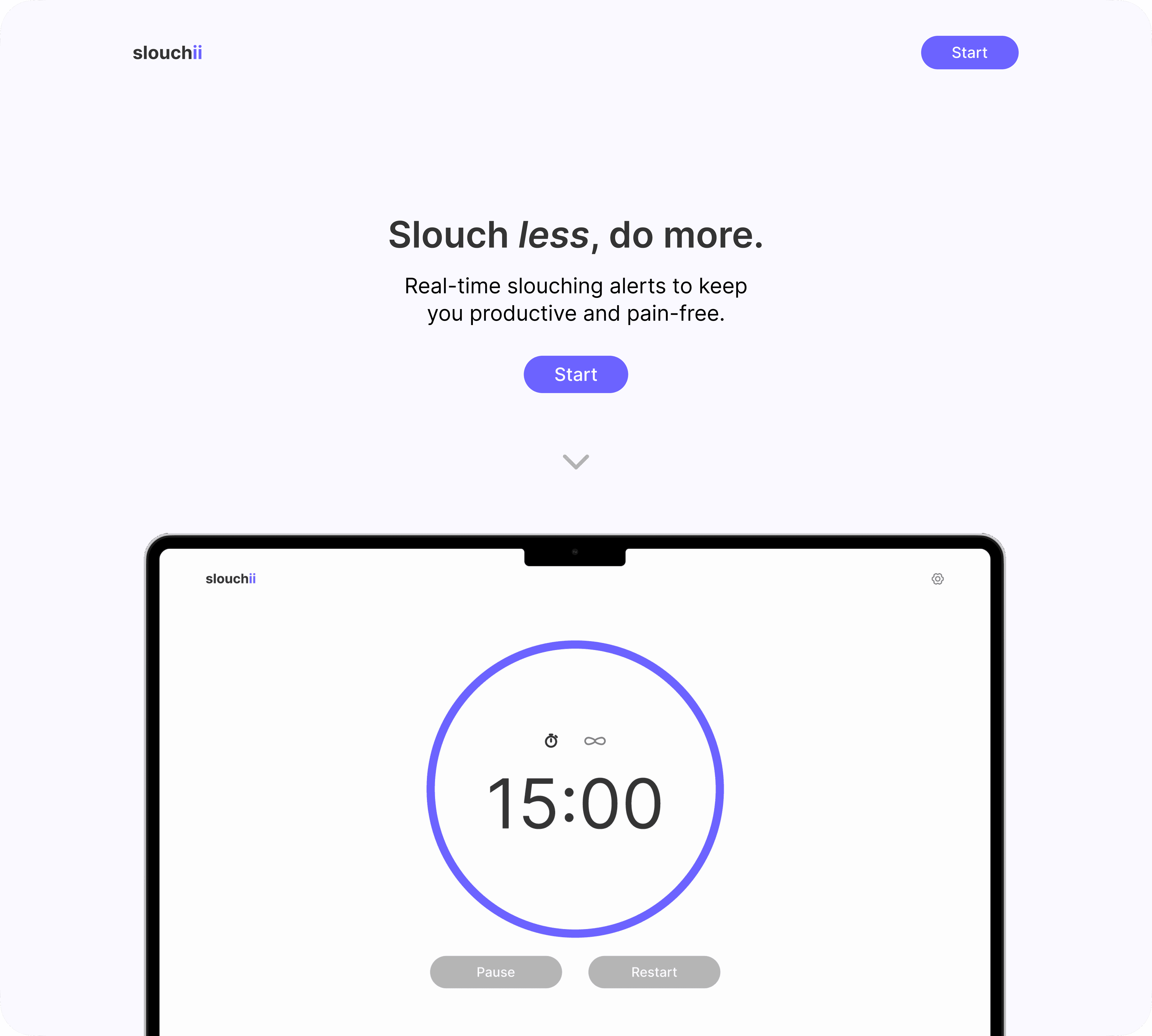
hello iris
about
Hello iris is an ambitious personal project that aims to put an end to voice commands. Inspired by new emerging technologies (i.e. Meta's VR glasses), design systems (i.e. Apple's liquid glass), and my passion for pushing the status quo, this project serves to change the way users interact with technology.
Our goal is to build a product that enables seamless handoffs between what you see and your devices through leveraging image recognition and machine learning software. For instance, imagine a world where a timer starts on your phone automatically as it detects an egg and boiling water–replacing siri, getting better over time.
No more awkward hey siri's and no more overcooked eggs. The future is near.
problem
Let's face it, relying on voice commands for real-life tasks in 2025 feels awful.
Your voice commands are ignored half the time, it requires extremely rigid phrasing, it's disruptive to your workflow, and you can't use it in public without disturbing others.
Given the technological landscape—particularly the progression of AI and its ability to adapt based on user data and context, voice prompted assistance feel like a relic of the past.
"Hey Siri, what's the weather?" might've been innovation back in the early 2000's, but it's now collecting dust. Let's change that.
opportunity
Although technology was the biggest bottleneck 10… 15 years ago, the landscape has dramatically shifted since then.
Take Meta's "Segment Anything Model" (SAM), for instance—it enables highly sophisticated video processing and object segmentation. If that's the case, why are we still relying on outdated tech and processes?
With emerging technologies, evolving design systems, and a shift in public sentiment toward tech, our goal is to create a cohesive, truly seamless experience that improves people's lives—often without them even realizing it.
What if you got a reminder when your water is boiling—without asking? Or if the weather was read out to you the moment you opened your window blinds in the morning? Let’s completely offload mental clutter as we step into the new age.


currently building
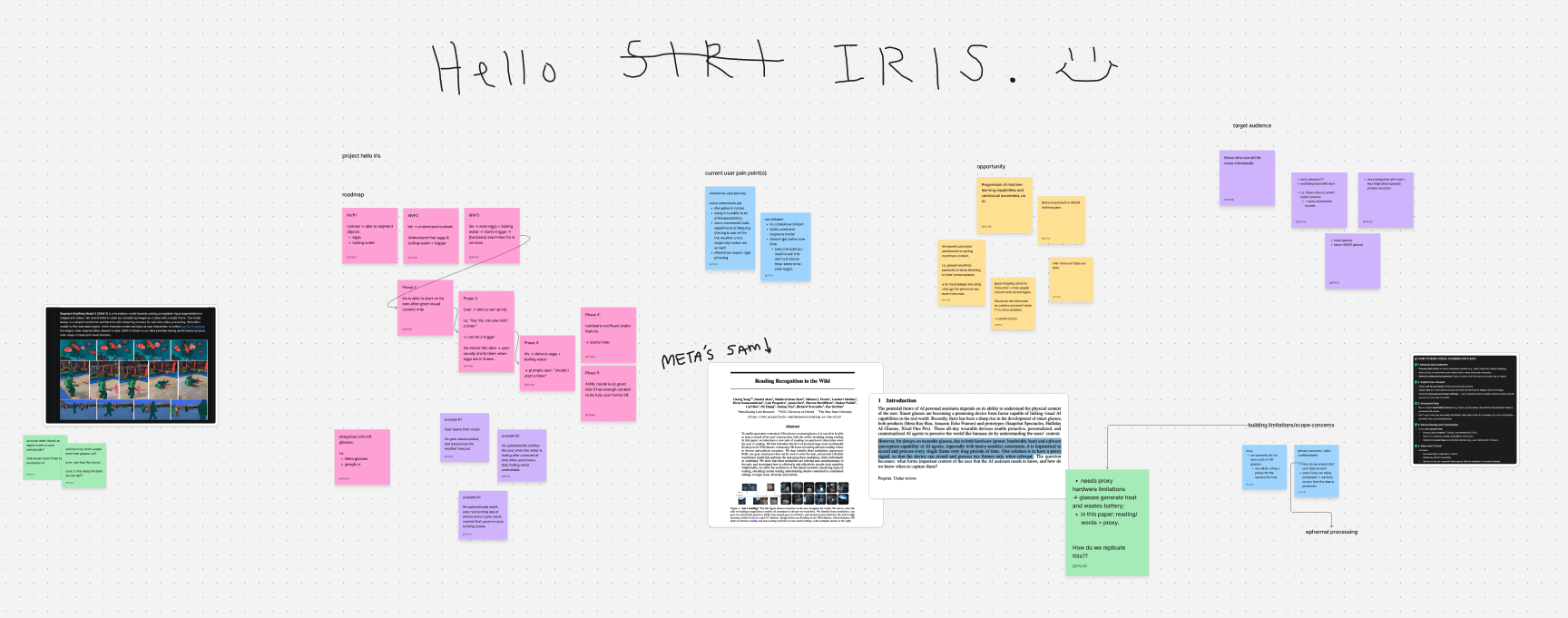
Currently, we're in the midst of building our MVP.
Expect to see a working prototype soon. Our MVP will have four very distinct checkpoints:
Image recognition: be able able to identify and segment boiling water and an egg.
Understanding context: understand the need for a "trigger" upon successful image identification.
Starting a timer: timer is automatically set up on your phone upon image identification via the external camera.
Contextual improvement: tune the model to start adapting to physical queues. (i.e. does the user eat eggs every morning?)